Optimizing the Recovery Time
Every hour a rural highway stays closed after a landslide or flood costs the local economy in lost freight, delayed emergency services, and stranded travelers. Oregon’s rural road network is enormous and Clatsop County alone has over 3,000 miles of highway and disasters don’t arrive on a schedule. Landslides cluster after winter rain. Wildfires drop debris across forest roads in summer. Snowstorms require repeated plowing passes through the night. And every piece of equipment sent to one disaster is a piece of equipment not available for the next one.
ODOT manages this resource allocation problem every year, largely through experience and intuition. This project asks a different question: what if you could simulate thousands of disaster scenarios and find the allocation strategy that minimizes total road closure time across all of them?
That’s the master’s capstone I’m building, a discrete-event simulation of ODOT’s disaster response system for Clatsop County, grounded in real GIS road network data and stochastic disaster generation, with the goal of training a reinforcement learning agent to make better dispatch decisions than any human-designed heuristic.
The Simulation
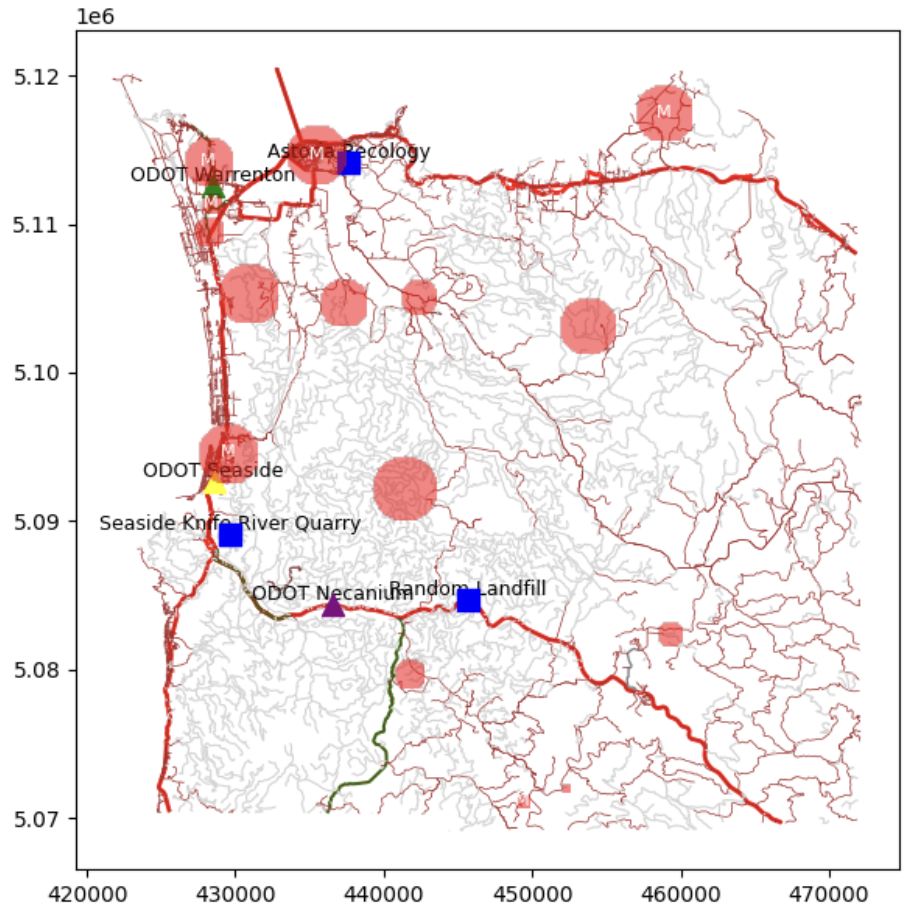
The core of the project is a SimPy 1 -based discrete-event simulation that models the full disaster response lifecycle: detection, resource dispatch, travel time to the site, clearance work, and debris disposal. Every component is parameterized from real data, equipment types (excavators, trucks, snowplows) with realistic speeds and fuel consumption, depot locations with limited capacity, and disaster events generated from Oregon’s actual seasonal patterns.
The road network comes from Clatsop County GIS shapefiles, parsed into a graph using NetworkX 2 , with edge weights derived from real road distances. When a disaster occurs and a resource needs to be dispatched, the simulation uses Dijkstra’s algorithm 3 to find the actual shortest path through the road network, not a straight-line approximation. If the road between a depot and a disaster site is itself closed by another event, the routing adapts. This geographic realism matters: a resource 10 miles away by road might be 30 minutes of travel; a resource 15 miles away on a mountain pass might be 90.
Disasters are generated stochastically from seasonal probability distributions, more landslides in winter and spring, more wildfire debris in summer and fall, snow events concentrated in the mountain passes. The simulation runs for configurable durations, typically multiple years, so that budget planning and resource positioning decisions can be evaluated across the full range of conditions the system will face, not just the average year.
Heuristic Policies and the Policy Switcher
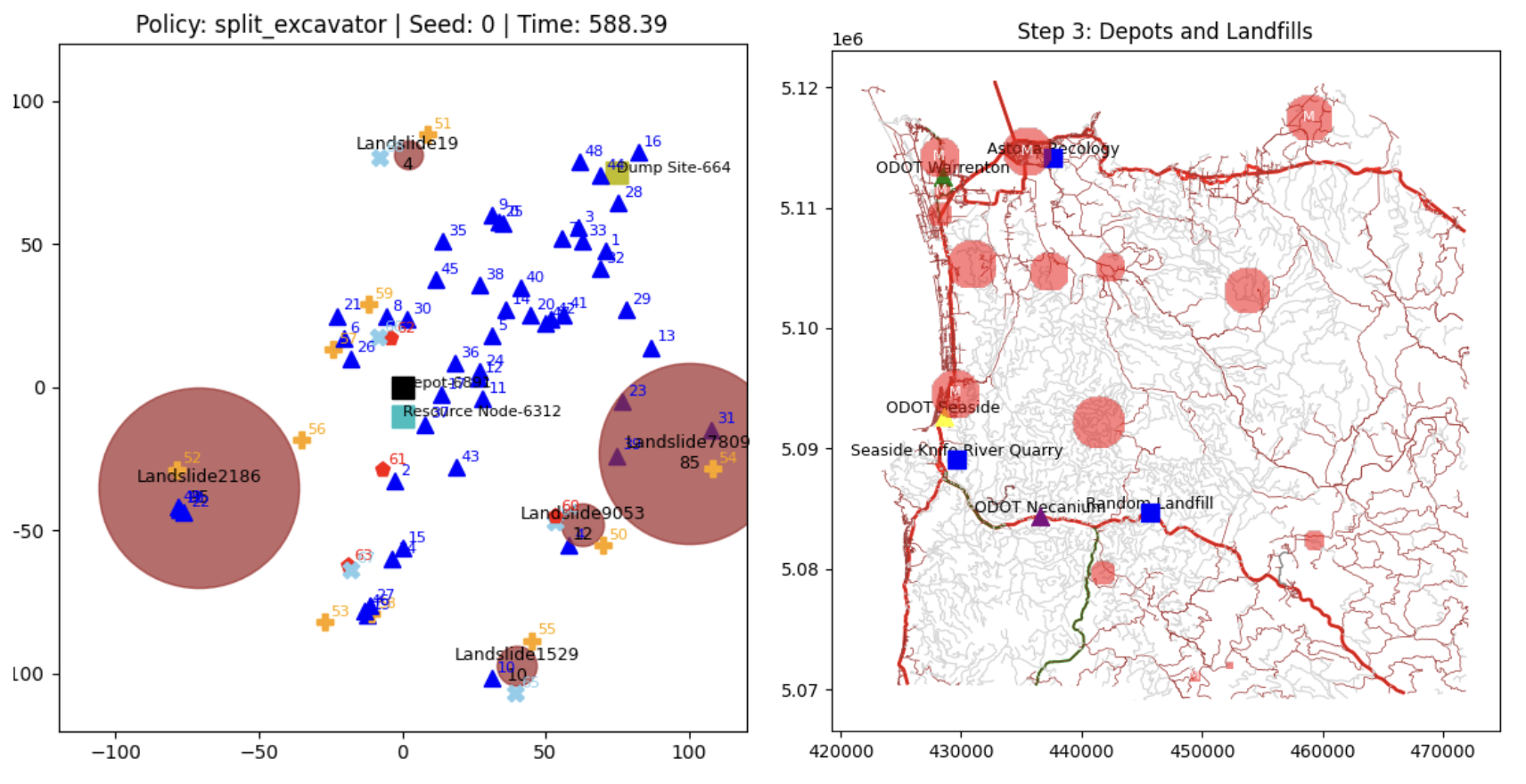
Before training an RL agent, the first goal was to understand what good human decision-making looks like and to create a meaningful baseline to eventually beat. The simulation includes a library of dispatch policies: hand-crafted heuristics that answer the question “given the current state, which resource goes to which disaster?”
Some examples from the policy library:
| Policy | Strategy |
|---|---|
| Closest First | Minimize travel time, send the nearest available resource |
| Largest First | Prioritize clearing the biggest blockages first |
| Chain | Anchor heavy equipment to large jobs, use lighter units for small ones |
| Balanced Ratio | Maintain an optimal truck-to-excavator ratio at each active site |
| Tournament | Simulate all possible assignments, pick the mathematically optimal one |
Each policy was benchmarked individually across hundreds of simulation runs. The results are instructive, no single policy dominates. Closest First is excellent when disasters are spread out and travel time is the bottleneck. Largest First performs better when multiple simultaneous events compete for the same equipment. The right strategy depends on the current state of the simulation.
That observation led directly to the Policy Switcher architecture. Rather than committing to one heuristic, the switcher tests every available policy at each decision point by running each one forward on a clone of the current simulation state and measuring which produces the best outcome. It then uses the winning policy for the next actual decision. I recently extended this with a depth counter, allowing the switcher to search recursively by evaluating not just the immediate next step but several steps ahead, performing a partial tree search over the policy space.
The result: the Policy Switcher consistently outperforms any individual static policy across all tested scenarios. It’s a meaningful intermediate milestone showing proof that the simulation captures enough real structure to differentiate between decision strategies.
The Path to Reinforcement Learning
The Policy Switcher is an intermediary step, not the end goal. The ultimate objective is a trained reinforcement learning agent that learns dispatch strategies directly from simulated experience so one that can discover patterns and edge cases that human heuristics miss entirely.
The simulation is wrapped as a Gymnasium 4 -compatible environment: the agent observes the current simulation state as a feature vector, selects a discrete action (which disaster to respond to next), and receives a shaped reward signal based on road closure time, population impact, and budget consumed. This makes the environment compatible with standard RL libraries including Stable Baselines3 and Ray RLlib.
The honest current challenge is that the simulation isn’t yet stochastic or dynamic enough to make RL training meaningful. When the environment is too predictable, hand-crafted heuristics will always perform well because there’s not enough variance for a learned policy to find an edge. Making the simulation more realistic with more complex disaster interactions, more dynamic resource constraints, more realistic seasonal variability, is the active development work that precedes serious RL training.
Key Contributions (So Far)
- Built a discrete-event simulation of ODOT’s disaster response system using SimPy, modeling equipment dispatch, travel, clearance, and disposal across a multi-year horizon
- Parsed Clatsop County GIS shapefiles into a navigable road network graph with Dijkstra-based routing for accurate travel time calculations
- Implemented and benchmarked 10+ dispatch heuristic policies, establishing baselines for resource allocation performance across varied disaster scenarios
- Designed the Policy Switching architecture, a simulation-cloning, multi-step lookahead system that consistently outperforms any individual static policy
- Built a Gymnasium-compatible RL environment interface connecting the simulation to standard deep RL training libraries