A life long dream
I was in high school watching YouTube videos of AI agents learning to walk, or navigate a track in Trackmania, or play simple games from scratch and I thought: I could do that in Minecraft. Not as a research project. Not for class. Just because it seemed like the most interesting thing a person could possibly build.
So I tried. The Java reinforcement learning package I found didn’t work on my machine. I tried again a couple years later. Failed again. So I took a detour and built a Minecraft skin generator using diffusion models instead, which worked, which helped me actually understand deep learning and filed the Minecraft RL idea away.
Then, at the tail end of my bachelor’s degree and the very start of my master’s, I decided: I’m doing it. I know how to use PyTorch 1 now. I know what an RL environment looks like. I know what I’m building.
Why No Python
The obvious path was to use something like MineRL 2 which is an existing framework that bridges Python RL libraries to Minecraft. I didn’t want it.
Partly because I wanted to understand and own every layer of the system myself. But mostly because I had a vision for what this project eventually becomes: an agent running live on a real Minecraft server, playing against actual people. That requires speed. Bridging Python and Java over a socket or subprocess introduces overhead. The game server runs at 20 ticks per second. The training loop needs to stay in sync with that. Any external process is a liability.
While searching for ways to run PyTorch natively in Java, I found JavaCPP 3 . Its a library that generates Java bindings for native C++ code via JNI. It has presets for LibTorch 4 , which is PyTorch’s C++ distribution. That was the key to access the full PyTorch tensor and autograd API directly from Java, with no Python process anywhere in the stack. The training loop runs synchronously with the server tick, sharing memory directly with the game engine.
The Architecture
The project is a Paper 5 server plugin. When the server starts, the plugin initializes the neural network, sets up the training environment, and begins stepping through the RL loop on every game tick.
The agent uses Proximal Policy Optimization (PPO) with a Long Short-Term Memory (LSTM) network that gives the agent memory across timesteps. This was based on the CleanRL 6 implementation of PPO for Atari games. The memory matters because Minecraft is a partially observable environment: the agent can only see what’s in front of it at any given moment, so it needs to remember what it saw a few ticks ago to make good decisions. A plain feedforward network would not remember what it saw.
The action space is mixed: discrete outputs for movement (WASD keys) and continuous outputs for camera rotation (yaw and pitch). Getting both to work together inside a single PPO update required some care in how the losses are combined, but it mirrors how a human actually plays with button presses plus mouse movement.
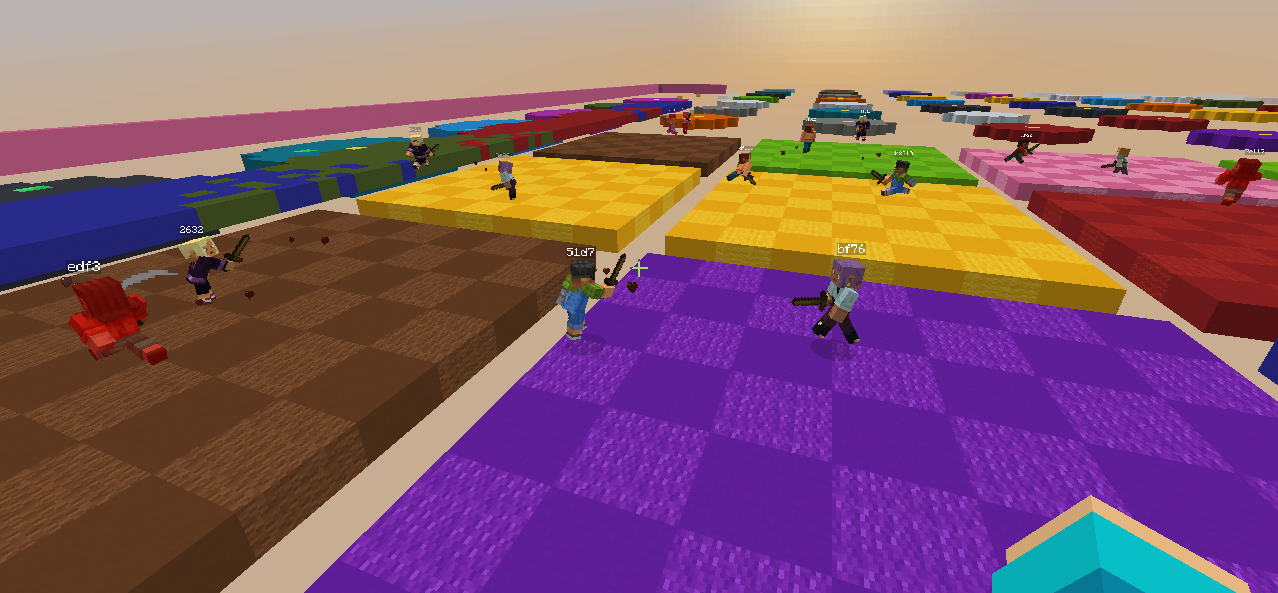
Vectorized environments run multiple agents simultaneously on a single server thread. Each agent has its own independent observation and action, but they’re batched together into tensors so the forward pass and gradient update happen once per tick across all of them. This is how standard RL training scales. Instead of waiting for one episode to finish before learning, you collect experience from N agents in parallel and learn from all of it at once. For the self-play combat experiment, two environments observe each other: one agent’s position and health become part of the other’s observation vector, and they’re pitted against each other directly.
The In-Game Debug UI
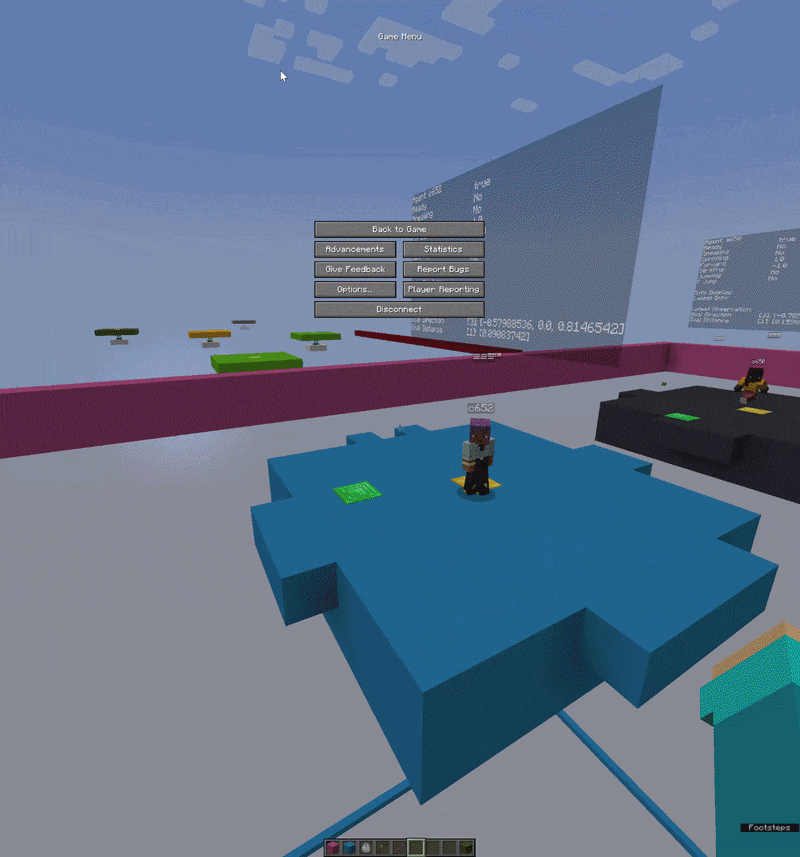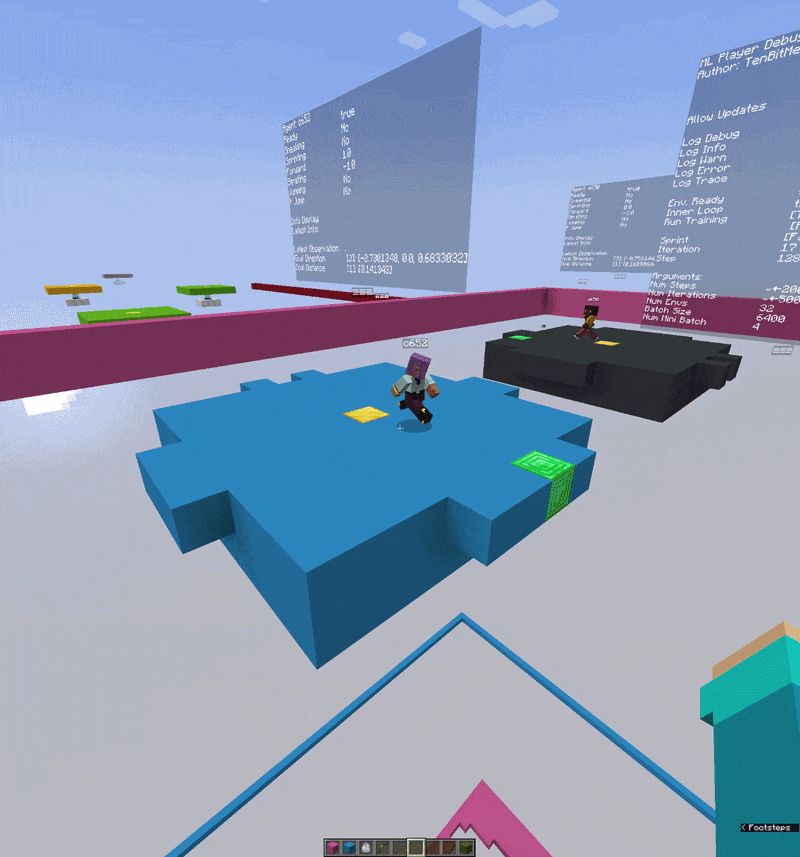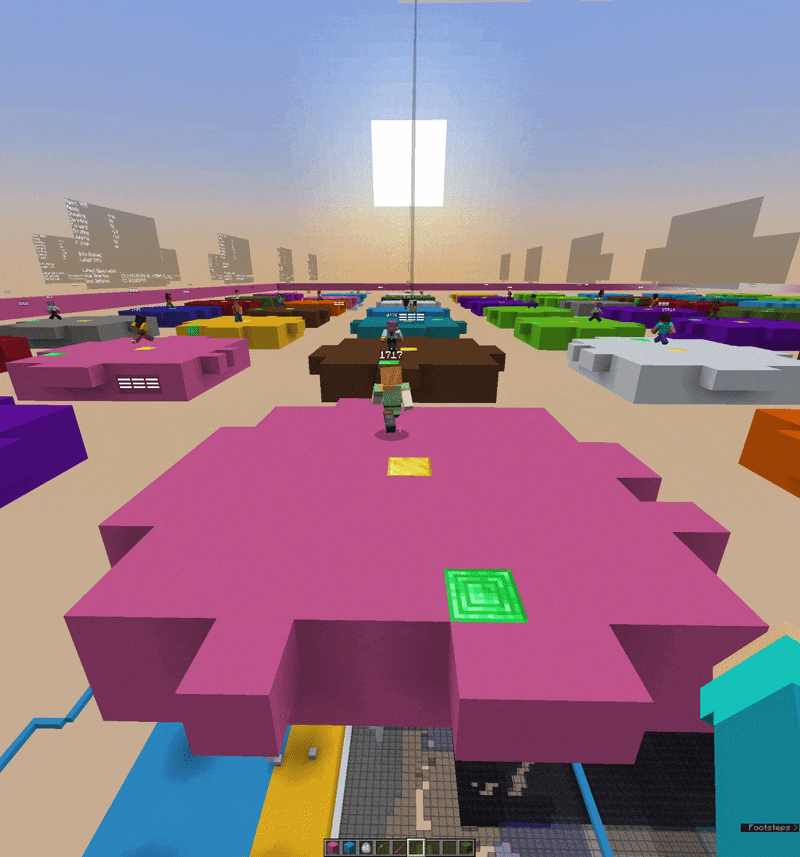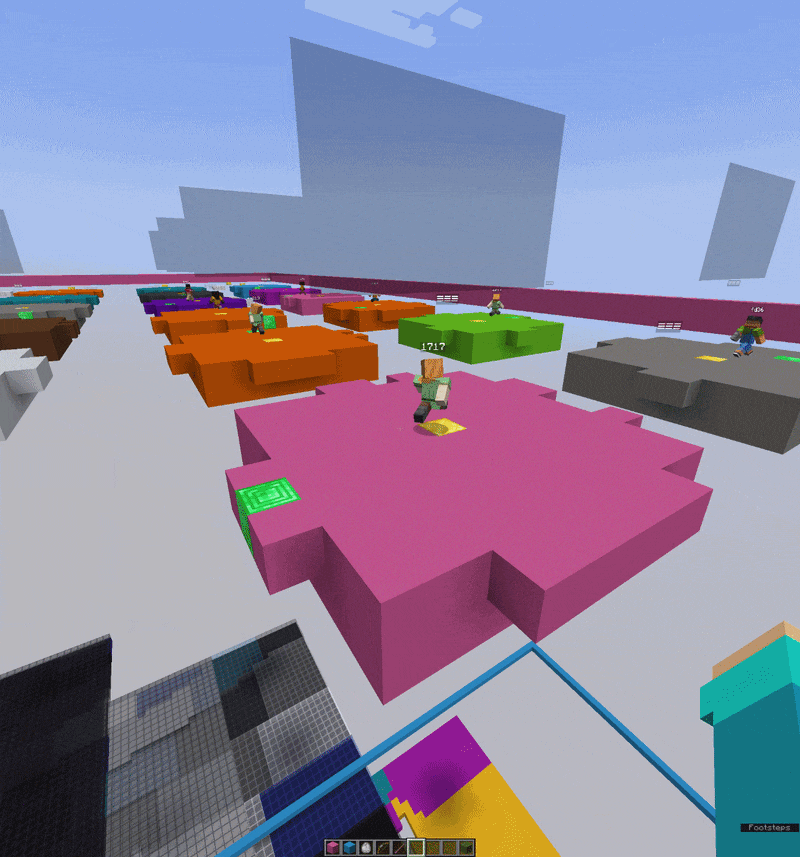
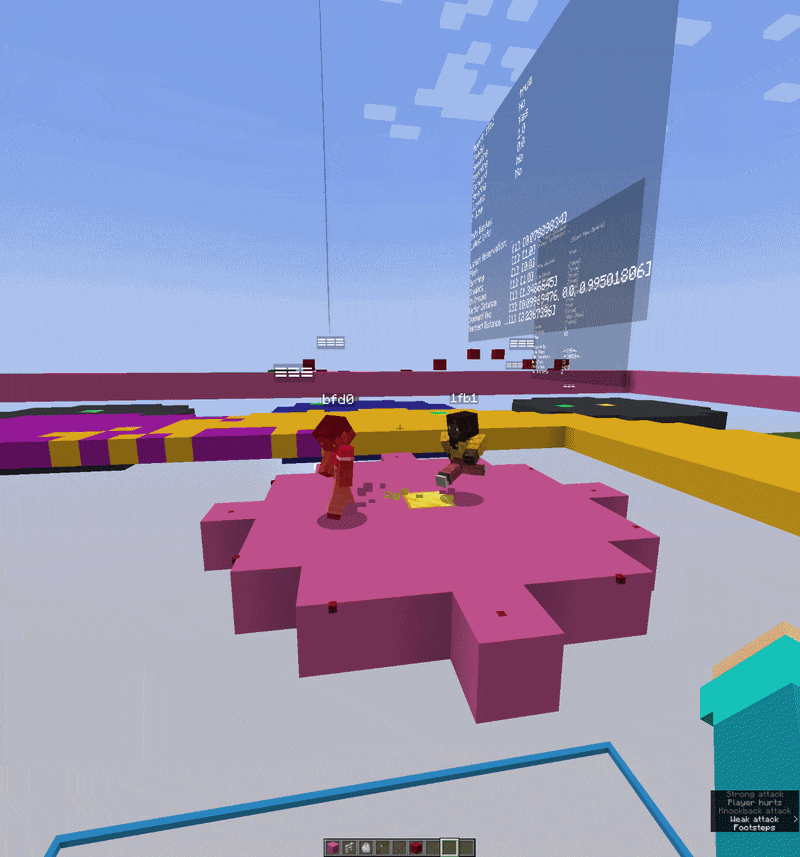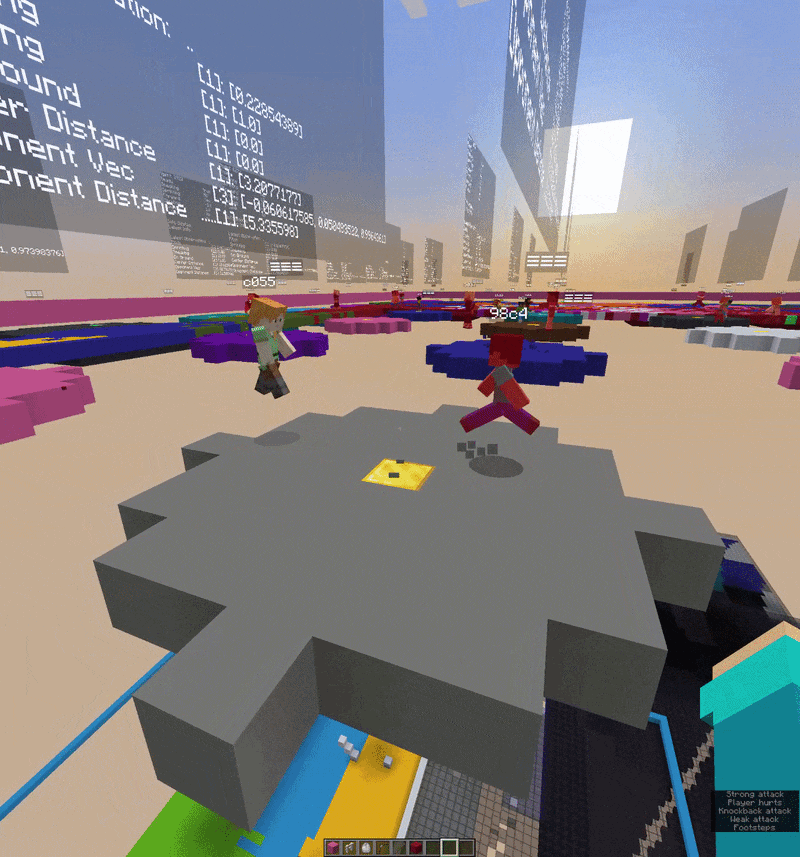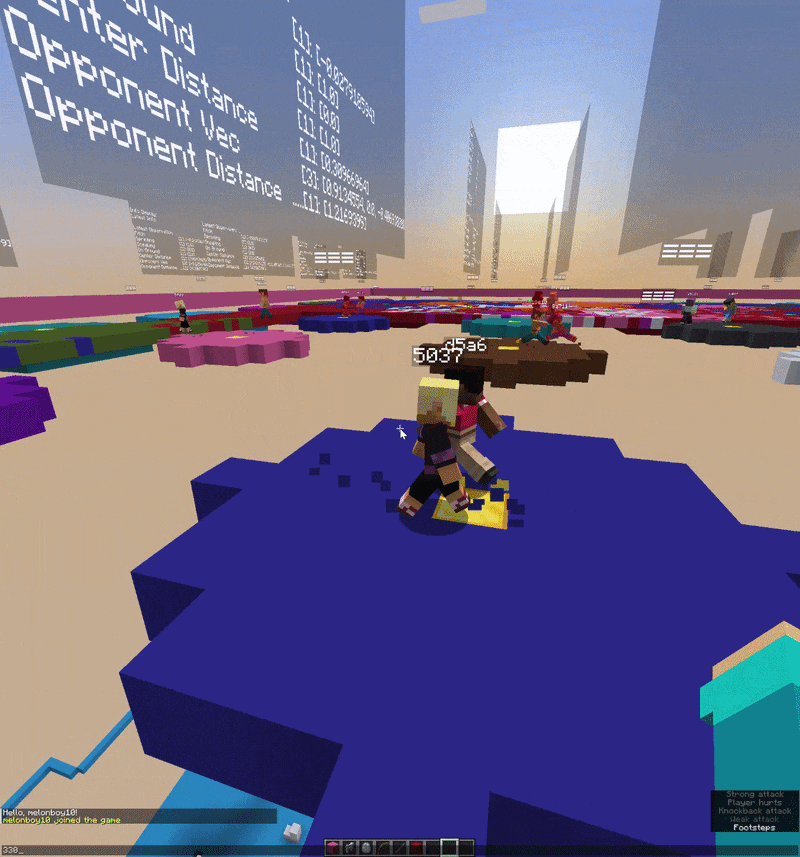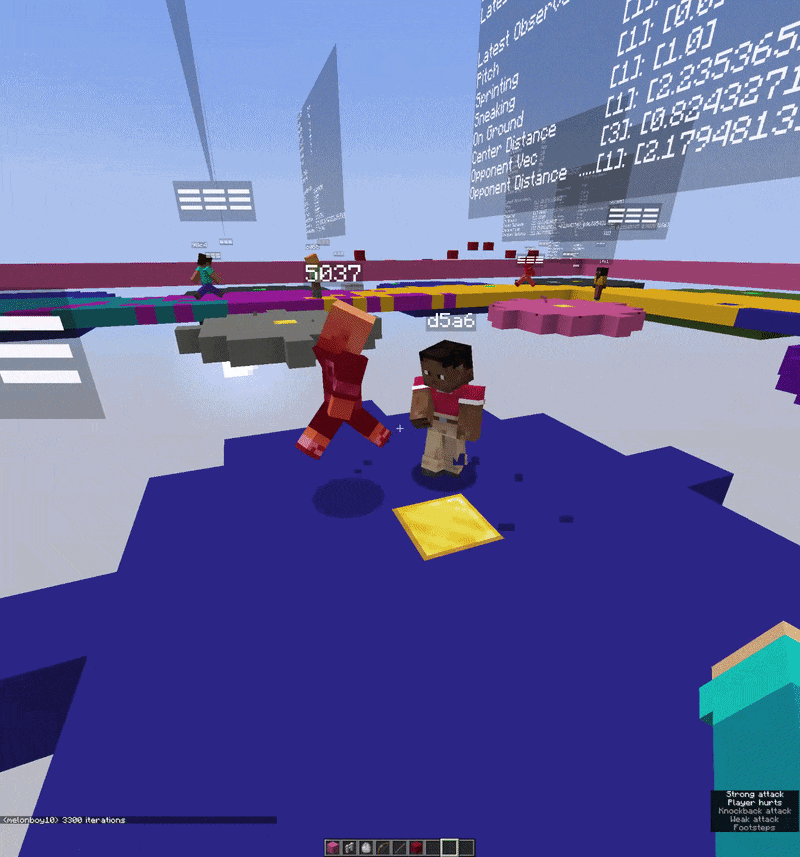
One of the more unusual parts of this project is the visual debugger. Rather than reading training logs in a terminal, I built a 3D in-game debug interface using Minecraft’s TextDisplay entities that show floating text objects that exist in the world as actual entities.
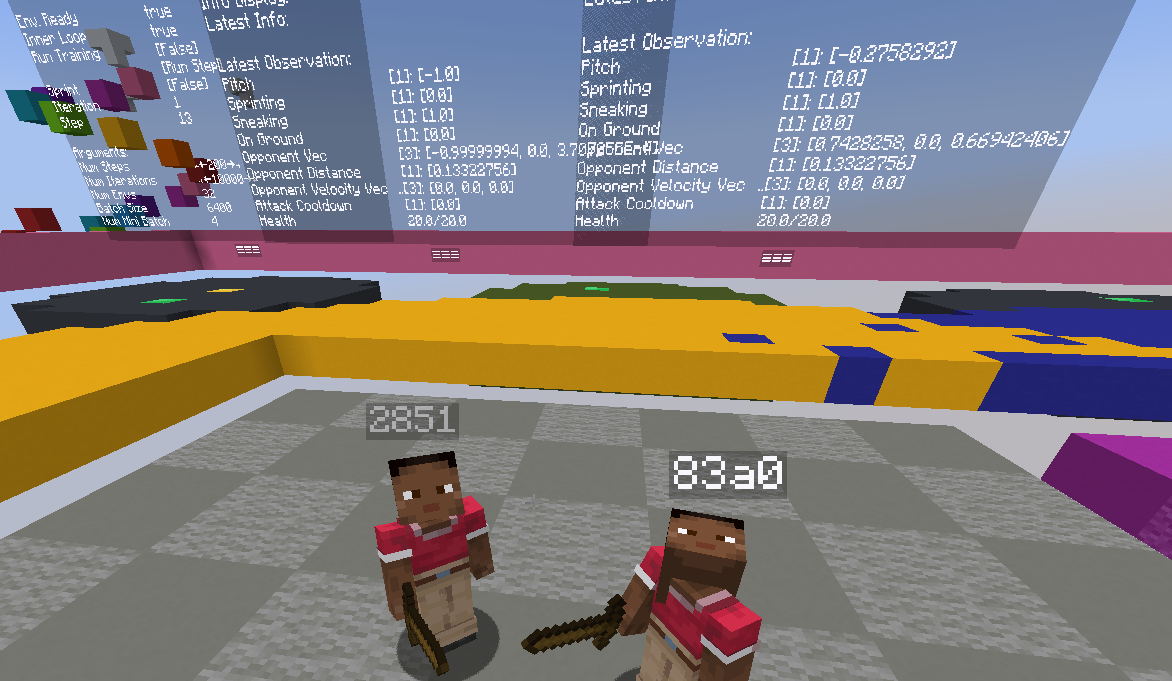
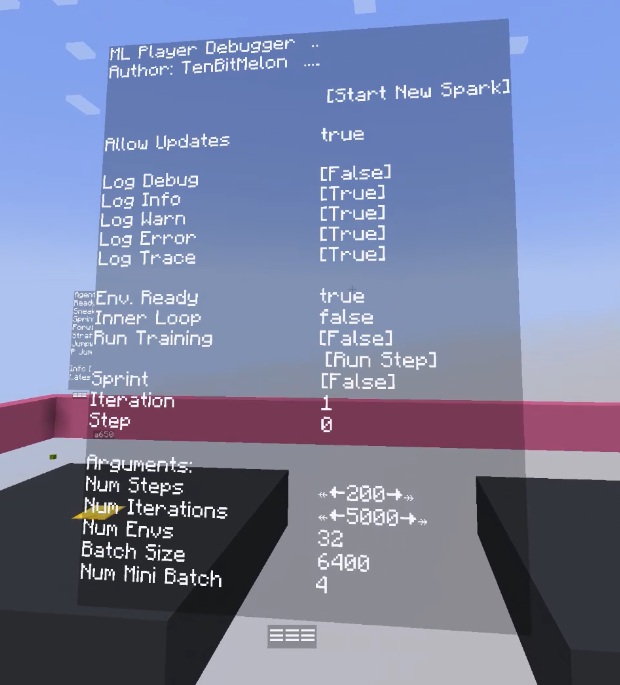
Above each agent, floating in 3D space, you can see live tensor values, action probability distributions, reward signals, and training metrics all updating every tick. It’s well integrated and extremely useful. When something is going wrong with the reward function or the action probabilities are collapsing, you can literally walk up to the agent and read the numbers hovering over its head.
The Memory Problem
Here are the open problems in this project: it still leaks memory.
The root issue is the boundary between the JVM and native LibTorch code. When Java allocates a tensor, regardless of size, or if it is temporary intermediate in a calculation, that allocation often ends up on the GPU through LibTorch. The JVM’s garbage collector doesn’t know about GPU memory. From Java’s perspective, a tensor object is tiny pointer. It doesn’t prioritize collecting it. Meanwhile, on the GPU side, those objects accumulate.
The fix is to wrap operations in PointerScopes 7 which is JavaCPP’s mechanism for explicitly deallocating all native references when a scope exits and to do as many operations in-place as possible to avoid allocating new tensors at all. I’ve wrapped every hot path I can find. I’ve set every JVM flag available to cap memory usage and force more aggressive collection. I’ve restructured the training loop to minimize short-lived allocations.
And it still leaks. On an eight-hour training run, it will sometimes crash because the GPU runs out of memory. The leak rate is slow enough that shorter runs are fine, but it’s an unsolved problem and I know it.
This is, genuinely, one of the hardest debugging experiences I’ve had.
What It’s Learned So Far
The v0.1.0 agent learned to walk toward a goal block and orient its camera toward it. That sounds simple, but watching it figure out that rotating toward the target and then walking forward produces reward, and gradually learning to do that more efficiently across a randomized environment, is genuinely satisfying. The mean magnitude of motion spikes right at the moment the crack appears, and the model knows not to invent motion where there’s no texture. That it works at all, end to end, from game engine to tensor to gradient update and back, is the thing I’m most proud of.
The v0.2.0 experiment moved into self-play combat where two agents in the same world, observing each other, each trying to win a simple PvP encounter. It only trained for a short time and the behavior is still very rough, but the infrastructure works. Two agents, two independent decision streams, shared world, batched into one tensor update per tick.
Key Contributions
- Implemented PPO + LSTM entirely in Java using LibTorch via JavaCPP, with no Python dependency or external process
- Designed a vectorized environment system that runs multiple independent agents simultaneously, batched into single tensor operations per server tick
- Built a mixed discrete/continuous action space for simultaneous WASD movement and camera rotation control
- Engineered a live in-game 3D debug UI using TextDisplay entities to visualize tensor values, action probabilities, and reward signals in real time
- Implemented and iteratively refined self-play combat environments where two agents observe and compete against each other in a shared world